The MIT/Tuebingen Saliency Benchmark will be soon host the COCO-Freeview benchmark, adding another exciting dataset for models to compete on!
The MIT/Tuebingen Saliency Benchmark will be extended to include other eye movement benchmarking tasks! We'll start with scanpath prediction in free-viewing and visual search settings.
MIT/Tuebingen Saliency Benchmark
This is the MIT/Tuebingen Saliency Benchmark. This benchmark is the sucessor of the MIT Saliency Benchmark and aims at advancing our understanding of what drives human eye movements. The benchmark hosts the MIT300 and the CAT2000 datasets for saliency model evaluation. In the future, we plan to extend the benchmark in several directions to help the community.
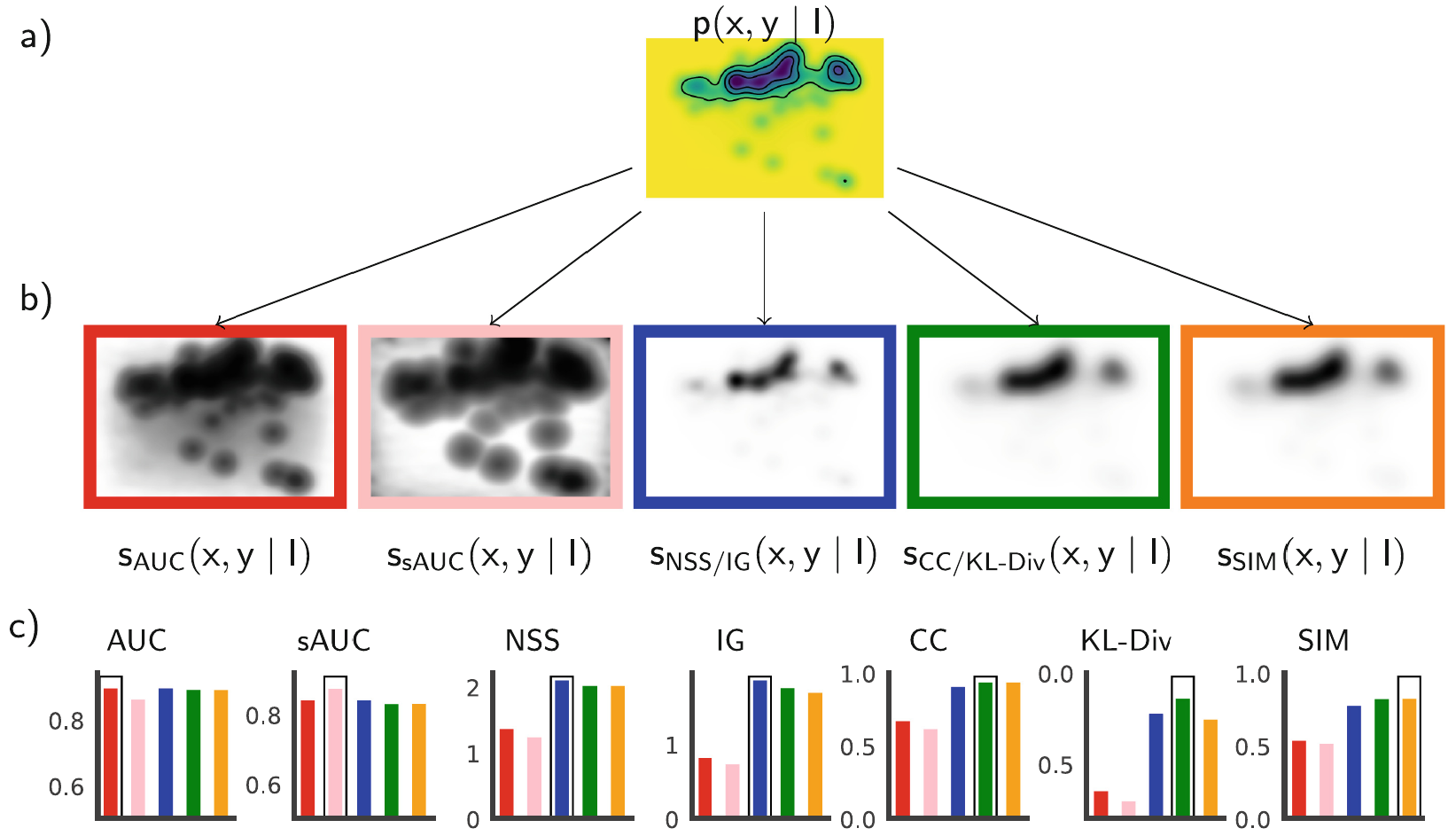
The main extension compared to the classic MIT Saliency Benchmark is that we now allow submission of models either as classic saliency maps (as in the past), or as fixation densities. The new prefered way of evaluating models is via the submission of probabilistic models predicting fixation densities. From those densities, metric-specific saliency maps can be derived which make model evaluation much more consistent. In nearly all cases, models perform better than with the classic evaluation since penalties due to saliency maps not matching the metrics are removed. For more details see Kümmerer et al, Saliency Benchmarking Made Easy: Separating Models, Maps and Metrics [ECCV 2018] and also here. However, of course the new Saliency Benchmark still supports evaluation of classic saliency maps as usual before.
website citation
@misc{mit-tuebingen-saliency-benchmark,
author = {Matthias K{\"u}mmerer and Zoya Bylinskii and Tilke Judd and Ali Borji and Laurent Itti and Fr{\'e}do Durand and Aude Oliva and Antonio Torralba and Matthias Bethge},
title = {MIT/Tübingen Saliency Benchmark},
howpublished = {https://saliency.tuebingen.ai/}
}
paper citations
@inproceedings{kummererSaliencyBenchmarkingMade2018,
title = {Saliency Benchmarking Made Easy: Separating Models, Maps and Metrics},
series = {Lecture Notes in Computer Science},
shorttitle = {Saliency Benchmarking Made Easy},
pages = {798--814},
booktitle = {Computer Vision – {ECCV} 2018},
publisher = {Springer International Publishing},
author = {K{\"u}mmerer, Matthias and Wallis, Thomas S. A. and Bethge, Matthias},
editor = {Ferrari, Vittorio and Hebert, Martial and Sminchisescu, Cristian and Weiss, Yair},
date = {2018},
}
@article{salMetrics_Bylinskii,
title = {What do different evaluation metrics tell us about saliency models?},
author = {Zoya Bylinskii and Tilke Judd and Aude Oliva and Antonio Torralba and Fr{\'e}do Durand},
journal = {arXiv preprint arXiv:1604.03605},
year = {2016}
}
@InProceedings{Judd_2012,
title = {A Benchmark of Computational Models of Saliency to Predict Human Fixations},
author = {Tilke Judd and Fr{\'e}do Durand and Antonio Torralba},
booktitle = {MIT Technical Report},
year = {2012}
}
Changelog
Here we indicate major changes in the benchmark.
- Jul. 23rd, 2023: gold standard scores for CAT2000 are available now. Also scores on CAT2000 changed slighly due to changes in the evaluation: we noticed that previously, we used empirical saliency maps with a wrong bandwidth, not matching those provided with the dataset. Fixing this changed the CC, KLDiv and SIM scores. Also, IG values changed because a wrong baseline score was used as offset. All models have been reevaluated accordingly, you can still find the old results here.
- Apr. 9th, 2021: CAT2000 dataset is available for evaluation again
- Nov. 2019: Launch of the new MIT/Tuebingen Saliency Benchmark as a successor to the MIT Saliency Benchmark, evaluating the MIT300 dataset
people
Matthias Bethge, University of TübingenAli Borji, University of Central Florida
Zoya Bylinskii, Massachusetts Institute of Technology
Fredo Durand, Massachusetts Institute of Technology
Laurent Itti, University of Southern California
Tilke Judd, Google Zurich
Matthias Kümmerer, University of Tübingen
Aude Oliva, Massachusetts Institute of Technology
Antonio Torralba, Massachusetts Institute of Technology